
第3回では、リファクタリング済みのFortranコードをPythonへ逐次的に移植し、アルゴリズムの移植は正しく完了したものの性能面での課題が明らかになりました。
本稿では、この性能問題を解決するため、まずプロファイラを用いてボトルネックを特定し、その後「ベクトル化(NumPy)」と「JITコンパイル(Numba)」という2つの異なるアプローチでコードの高速化を図ったプロセスと、その結果を報告します。
移植版Pythonコードのパフォーマンス分析
最適化の第一歩として、前回作成した移植版Pythonコードのパフォーマンスプロファイルを取得しました。このベースバージョンの分析には、Pythonの標準プロファイリングツールであるcProfileモジュールを使用し、800x800の行列でプロファイリングを実行しました。
python -m cProfile -o profile_base.pstat benchmark_base.py matrix_800x800_rand_uniform.binプロファイリング結果(抜粋):
11598927 function calls in 820.659 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1313696 798.401 0.001 798.401 0.001 dsvdc.py:3(drot1)
1 13.478 13.478 815.690 815.690 dsvdc.py:122(dsvdc)
1313696 2.337 0.000 3.052 0.000 dsvdc.py:72(drotg)
...分析:
- 総実行時間(プロファイラによる計測値): 820.6秒。 (この時間にはプロファイリング自体のオーバーヘッドが含まれるため、後述のベンチマーク結果とは異なります。)
- ボトルネック:
dsvdc.py内のdrot1関数が、総実行時間の約97%にあたる798.4秒を消費していました。この関数は130万回以上呼び出されており、処理全体のホットスポット(最も時間のかかっている箇所)であることが特定されました。
最適化アプローチと結果
特定されたボトルネックおよびアルゴリズム全体に対し、2つのアプローチで最適化を試みました。
アプローチ1:ベクトル化 (NumPy)
Pythonのforループで一つずつ処理していたデータを、NumPyの配列としてまとめて計算する「ベクトル化」を試みました。 ここでいうベクトル化とは、従来ループで個々に処理していた計算を、NumPyの配列演算や関数に置き換えることで、配列全体に対して一度に処理を行う手法です。 これにより、NumPyがC言語で最適化された実装を用いて演算を行うようになるため、高速化が実現されます。
drot1関数のベクトル化
まず、ホットスポットであるdrot1関数内のforループを、NumPyの配列演算に置き換えました。
変更前:
def drot1(n, dx, dy, c, s):
if n <= 0:
return
# ループ制御を0ベース化 (0 から n-1 まで)
for i in range(n):
dtemp = c * dx[i] + s * dy[i]
dy[i] = c * dy[i] - s * dx[i]
dx[i] = dtemp変更後:
def drot1(n, dx, dy, c, s):
if n <= 0:
return
# ループを使わず、配列全体に対して一括で演算(ベクトル化)
temp = c * dx[:n] + s * dy[:n]
dy[:n] = c * dy[:n] - s * dx[:n]
dx[:n] = temp この変更だけでも、800x800行列を用いた場合で、プロファイラ上での実行時間比較では約29倍の高速化が確認できました。
dswap1関数のベクトル化
ホットスポットではありませんが、dswap1関数もループ処理が含まれており、NumPyで簡潔に書き直せるため、以下のようにベクトル化しました。
def dswap1(n, dx, dy):
if n <= 0 or dx is dy:
return
tmp = dx[:n].copy()
dx[:n] = dy[:n]
dy[:n] = tmpdsvdcメインルーチンのベクトル化
次に、計算のメインルーチンであるdsvdc関数内のループに対しても、ベクトル化を試みました。
dsvdc関数では、行列の変形処理において列や行を個別に更新するforループが使用されていました。これらのループ処理をNumPyの行列演算(np.dot、np.outer)を用いた一括処理に置き換え、列変換と行変換の両方でベクトル化を実装しました。
列変換のベクトル化部分(抜粋)
# オリジナル(ループ処理)
for j in range(lp1, p + 1):
t = -np.dot(vec_l, x[l:n, j]) / vec_l[0]
x[l:n, j] += t * vec_l
# ベクトル化後(一括処理)
matrix_sub = x[l:n, lp1:p+1]
t_vec = -np.dot(vec_l, matrix_sub) / vec_l[0]
x[l:n, lp1:p+1] += np.outer(vec_l, t_vec)行変換のベクトル化部分(抜粋)
# オリジナル(2つのループ処理)
work[lp1:n] = 0.0
for j in range(lp1, p + 1):
work[lp1:n] += e[j] * x[lp1:n, j]
for j in range(lp1, p + 1):
x[lp1:n, j] -= (e[j]/e[lp1]) * work[lp1:n]
# ベクトル化後(行列演算)
work[lp1:n] = np.dot(x[lp1:n, lp1:p+1], e[lp1:p+1])
x[lp1:n, lp1:p+1] -= np.outer(work[lp1:n], e[lp1:p+1] / e[lp1])dsvdcに上記のベクトル化を実装し、1600×1600の行列を用いて実行時間を計測したところ、約125秒かかりました。これは、このベクトル化前のコード(つまり、drot1とdswap1のみをベクトル化したコード)の実行時間である約111秒を上回っており、期待に反して性能が低下する結果となりました。
この性能低下は、元のコードが既存の配列を直接更新する効率的なインプレイス処理であったのに対し、ベクトル化版では中間的な配列が繰り返し生成される形となり、その生成コストが高速化のメリットを上回ったためではないかと考えています。
この結果から、dsvdc関数については元のループ構造を維持することとし、最終的なベクトル化版ではdrot1とdswap1関数のみをベクトル化しコードを採用しました。
アプローチ2:JITコンパイル (Numba)
次に、ベクトル化とは異なる最適化手法として、NumbaのJITコンパイル機能を用いてPython関数を実行時に機械語へコンパイルするアプローチを試みました。 関数の高速化を行うには、最適化したい関数に@njitデコレータを付与します。これにより、関数が初めて呼び出される際、その場で(Just-in-Time, JIT)高速な機械語にコンパイルされるため、処理が大幅に高速化されます。
drot1関数のJIT化
まず、元のベースバージョンのdrot1関数に@numba.njitデコレータを追加しました。
変更前:
import numpy as np
def drot1(n, dx, dy, c, s):
...変更後:
import numpy as np
import numba
@numba.njit
def drot1(n, dx, dy, c, s):
...この変更だけで、800x800行列を用いた場合で、(プロファイラ上の計測で)約41倍の高速化が確認できました。これはdrot1のみをベクトル化した際の結果(約29倍)を上回るものでした。
モジュール全体のJIT化
drot1関数のJIT化によって実行時間は大幅に短縮できましたが、さらなる性能向上を目指して、今度はその呼び出し元であるdsvdc関数本体、および、そこから呼び出されるヘルパー関数(dswap1やdrotg)についても同様に@njitデコレータを付与し、JITコンパイルの対象範囲を拡大しました。
なお、コンパイル結果をキャッシュして2回目以降の実行時のオーバーヘッドを削減するため、各デコレータには cache=True オプションを付与しました。
import numba
@numba.njit(cache=True)
def drot1(...):
# ...
@numba.njit(cache=True)
def dswap1(...):
# ...
@numba.njit(cache=True)
def drotg(...):
# ...
@numba.njit(cache=True)
def dsvdc(...):
# ...ベンチマーク評価
3つの異なる実装について、複数の行列サイズでパフォーマンスを測定し、実行時間を比較しました。 なお、Numba(JIT)コードの評価については、初回コンパイルの影響を避けるため、一度実行してキャッシュが生成された状態で計測を行っています。 各実装の詳細は以下の通りです。
実装バージョンの説明
- ベースコード: オリジナルのFortranコードをそのままPythonに移植したベースバージョン
- ベクトル化コード: drot1, dswap1にNumPyベクトル化を適用したバージョン
- Numba(JIT)コード: 全ての関数にNumba JIT(Just-In-Time)コンパイル(njit with cache=True)を適用したバージョン
ベンチマーク結果
各行列サイズにつき3回実行した最速時間を記録。括弧内の数値はベースコードに対する高速化倍率を示します。
| 行列サイズ | 逐次移植ベースコード | ベクトル化コード | Numba(JIT)コード |
|---|---|---|---|
| 100x100 | 1.735 s | 0.280 s (6.2 倍) | 2.574 s (0.7 倍) |
| 200x200 | 13.141 s | 1.216 s (10.8 倍) | 2.520 s (5.2 倍) |
| 400x400 | 100.958 s | 4.966 s (20.3 倍) | 2.628 s (38.4 倍) |
| 800x800 | 764.388 s | 23.084 s (33.1 倍) | 3.893 s (196.3 倍) |
| 1600x1600 | 5902.190 s | 110.484 s (53.4 倍) | 17.708 s (333.3 倍) |
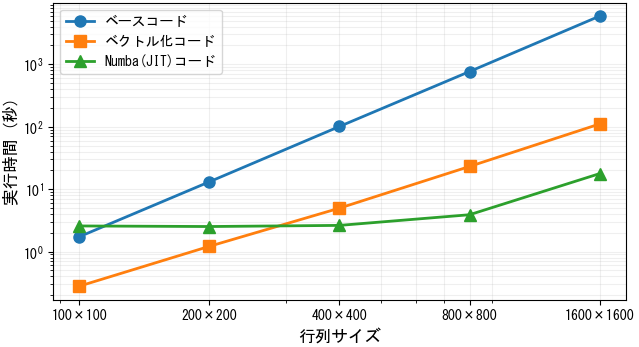
結果の考察:
ベクトル化およびJITコンパイルは、逐次実装されたベースのPythonコードの性能を大幅に改善しました。特に、モジュール全体をJITコンパイルしたアプローチは、行列サイズが大きくなるにつれて計算性能を大きく向上させました。
一方で、JITコンパイルにはコードの実行自体に一定のオーバーヘッドが存在します。小規模な行列では、このオーバーヘッドが計算時間の短縮効果を上回ってしまい、性能向上が限定的になります。実際に、100x100行列ではベースコードの実行時間を下回り、200x200行列でもベクトル化版に劣る結果となりました。
結論として、行列サイズが大きくなるほどJITコンパイルのオーバーヘッドは相対的に小さくなり、その効果が最大限に発揮され、ベクトル化版を大きく引き離す結果となっています。
まとめと次回予告
今回の検証では、プロファイリングを通じて性能のボトルネックを特定し、NumPyによるベクトル化とNumbaによるJITコンパイルを適用することで、Pythonコードの実行速度を実用的なレベルまでに向上させることができました。
特にNumbaを用いたJIT化は、元のPythonロジックをほぼ変更することなく、デコレータを追加するだけでFortranに迫る性能を達成できる場合があることを示しました。
次回、第5回「f2pyによるFortranコードのラッピング」では、既存のFortranコードをPythonから直接呼び出す「ハイブリッド連携」アプローチの1つ目として、f2pyを用いた手法を解説します。f2pyが提供する自動ラッパー生成の手軽さと、その利点・欠点について詳しく見ていきます。