
これまでのシリーズでは、FortranコードをPythonへ完全に書き換える「完全移行」の方針(方針A)を検証してきました。
今回からは、もう一つの方針である「ハイブリッド連携」(方針B)に焦点を当てます。ハイブリッド連携では、実績のあるFortranの計算ルーチンをそのまま活用し、「ラッパー」を作成することで、FortranのサブルーチンをPythonの関数として直接呼び出せるようにします。今回はその具体的な手法の一つ目として、NumPyに含まれるツールf2pyを用いたFortranコードのラッピングプロセスを取り上げます。このツールが提供する3つの利用方法に関して、その手軽さ、柔軟性、そして性能について見ていきます。同時に、環境構築の複雑さや長期保守における課題についても触れていきます。
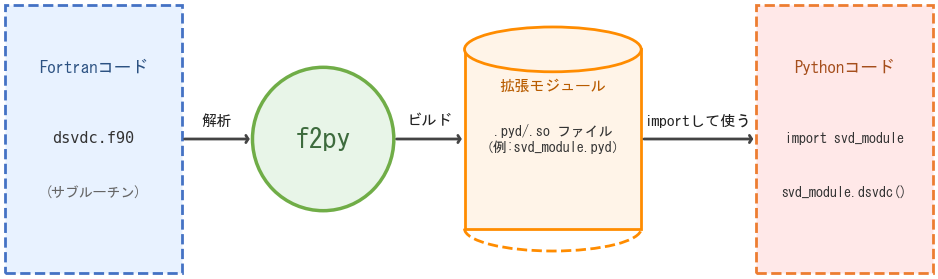
f2pyとは?
f2py(Fortran to Python Interface
Generator)は、Fortranコードを分析し、それをPythonから呼び出すためのインターフェース(ラッパーコード)を自動生成するツールです。
具体的には、Fortranソースコードからサブルーチンの引数の型、次元、intent(in, out, inout)属性といった情報を読み取り、それらを仲介するC言語(および必要に応じてFortran)のラッパーコードを生成します。そして、それらをコンパイルして、Pythonからimport可能な拡張モジュール(実体は.soや.pydといった共有ライブラリ)を作成します。
これにより、利用者はFortranとPython間のデータ型変換といった煩雑な詳細を意識することなく、作成された拡張モジュールをPythonで import するだけで、FortranのサブルーチンをあたかもPythonの関数であるかのように直接呼び出せるようになります。
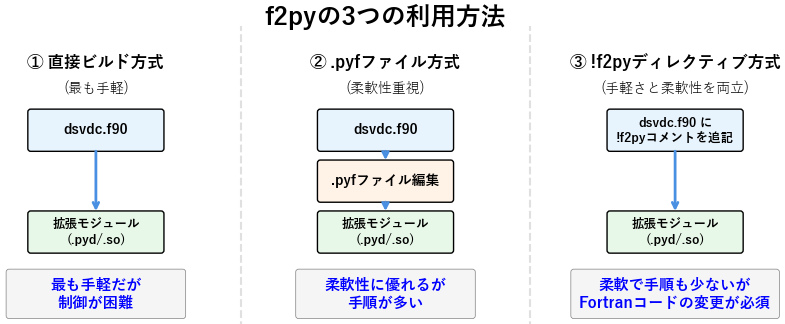
f2pyを利用する3つの方法
f2pyには、3つの利用方法があります:
- 直接ビルド方式:Fortranソースコードを一切変更せず、直接Pythonモジュールを生成する最も手軽な方法
.pyfファイル方式:インターフェース定義ファイル(.pyfファイル)を生成・編集してからビルドする方法!f2pyディレクティブ方式:Fortranソースに特殊なコメントを追加してビルドする方法
最初の直接ビルド方式は、例えば以下のように一行のコマンドで実行できます:
python -m numpy.f2py -c -m svd_module dsvdc.f90この方法は一見最も手軽ですが、f2pyによる引数の自動解釈が、意図しないインターフェースを生成する落とし穴になり得ます。例えば、f2pyの解釈によって引数の順番が入れ替わったり、出力用の配列が関数の戻り値として扱われたりすることがあります。このような予期せぬ挙動を防ぐため、実用的なコードでは、後述する2つの方法でインターフェースを明示的に制御することが推奨されます。
今回は、第1回で紹介したオリジナルのFortranコード(リファクタリング前のdsvdc.f90)を対象に、実用的な2つの方法(②.pyfファイル方式と③!f2pyディレクティブ方式)を実際に試してみました。
インターフェース定義ファイル(.pyf)を経由する方法
生成されたインターフェース定義(.pyfファイル)を編集することで、Fortranコードを一切変更せずにPython側のインターフェースを細かくカスタマイズできる利用方法です。
手順:
- インターフェース定義ファイルの生成:元のFortranソースコードからインターフェース定義ファイル(
.pyfファイル)を生成する。 - インターフェースのカスタマイズ:生成された
.pyfファイルを編集し、引数のintent属性や配列のサイズなどをカスタマイズする。 - Pythonモジュールのビルド:カスタマイズ済の
.pyfファイルからPython拡張モジュール(.soまたは.pydファイル)をビルドする。
この方法の一つの利点は、Fortranコードを一切変更することなく、開発者が意図するPythonインターフェースに細かく調整できることです。
ステップ1:インターフェース定義ファイル(.pyf)の生成
まず、Fortranコードからインターフェース定義ファイル(.pyfファイル)を生成します。
今回の例では、オリジナルのFortranソースファイルdsvdc.f90を対象に、以下のコマンドでインターフェース定義ファイルを生成します。
python -m numpy.f2py -h svd_module.pyf dsvdc.f90 only: dsvdcこのコマンドにより、dsvdc.f90ソースファイルが解析され、dsvdcサブルーチンのインターフェース情報(引数の型、次元など)が抽出されてsvd_module.pyfファイルに出力されます。
各オプションの意味は以下の通りです:
-m numpy.f2py: Pythonのnumpy.f2pyモジュールをコマンドとして実行-h svd_module.pyf: 出力するインターフェース定義ファイル名を指定only: dsvdc: ソースファイルの中からdsvdcサブルーチンのみを処理対象に限定(Pythonから呼び出すのはdsvdcのみであるため)
元のFortranコード(dsvdc.f90)のサブルーチン宣言部
SUBROUTINE dsvdc(x, n, p, s, e, u, v, job, info)
INTEGER, INTENT(IN) :: n
INTEGER, INTENT(IN) :: p
REAL (dp), INTENT(IN OUT) :: x(:,:)
REAL (dp), INTENT(OUT) :: s(:)
REAL (dp), INTENT(OUT) :: e(:)
REAL (dp), INTENT(OUT) :: u(:,:)
REAL (dp), INTENT(OUT) :: v(:,:)
INTEGER, INTENT(IN) :: job
INTEGER, INTENT(OUT) :: info自動生成された svd_module.pyf
! -*- f90 -*-
! Note: the context of this file is case sensitive.
module svd ! in dsvdc.f90
integer, parameter,optional :: dp=selected_real_kind(12, 60)
subroutine dsvdc(x,n,p,s,e,u,v,job,info) ! in dsvdc.f90:svd
real(kind=dp) dimension(:,:),intent(inout) :: x
integer intent(in) :: n
integer intent(in) :: p
real(kind=dp) dimension(:),intent(out) :: s
real(kind=dp) dimension(:),intent(out) :: e
real(kind=dp) dimension(:,:),intent(out) :: u
real(kind=dp) dimension(:,:),intent(out) :: v
integer intent(in) :: job
integer intent(out) :: info
end subroutine dsvdc
end module svd自動生成される.pyfファイルはそのまま変更せずに使える場合もありますが、多くの場合、開発者が意図する仕様にカスタマイズするための雛形として利用されます。
ステップ2:インターフェースのカスタマイズ
このステップでは生成された.pyfファイルを変更して、FortranのコードをPythonから「どのように呼び出せるようにするか」をカスタマイズします。
特に、引数の振る舞いを決めるintent属性の指定と、コード全体をまとめるモジュール定義は、このステップで重要です。
intent属性のカスタマイズ
intent属性は、Fortranの変数がPython側でどのように扱われるかを指定します。
intent(in)と指定すると、その変数はPythonから値を受け取る通常の入力引数になります。intent(out)と指定すると、その変数はPython関数の引数リストからは消え、代わりにFortranで計算された結果が関数の戻り値として返されます。intent(inout)と指定すると Pythonから渡した配列などが、Fortran側で直接書き換えられる入出力引数となります。
今回は、本シリーズの第3回・第4回で作成したPython版実装と同じインターフェース
info = dsvdc(x,n,p,s,e,u,v,job)
を実現することにします。自動生成された.pyfファイルには、出力配列(s,
e, u,
v)がintent(out)として定義されており、このままではこれらの配列が戻り値として扱われてしまいます。そこでこれらのintent属性をintent(inout)に変更し、Python側から引数として渡した配列が直接書き換えられるような仕様にカスタマイズしました。
モジュール定義
コード全体をpython module svd_moduleブロックで囲みました。これは必須の記述で、これにより、ファイル全体が
svd_module という単一のPythonモジュールとして明確に定義され、import
して利用できるようになります。
型の明確化
f2pyがinteger, parameter,optional :: dp=selected_real_kind(12, 60)というパラメータ定義から、real(kind=dp)が倍精度実数型であることを適切に解釈できず単精度実数になってしまっていたため、real(kind=dp)をより明示的なreal(kind=8)に書き換え、倍精度として認識されるようにしました。
カスタマイズ済の svd_module.pyf
! -*- f90 -*-
! Note: the context of this file is case sensitive.
python module svd_module
interface
module svd ! in dsvdc.f90
subroutine dsvdc(x,n,p,s,e,u,v,job,info) ! in dsvdc.f90:svd
real(kind=8) dimension(:,:),intent(inout) :: x
integer intent(in) :: n
integer intent(in) :: p
real(kind=8) dimension(:),intent(inout) :: s
real(kind=8) dimension(:),intent(inout) :: e
real(kind=8) dimension(:,:),intent(inout) :: u
real(kind=8) dimension(:,:),intent(inout) :: v
integer intent(in) :: job
integer intent(out) :: info
end subroutine dsvdc
end module svd
end interface
end python module svd_moduleステップ3:コンパイルとビルド
次にカスタマイズ済の.pyfファイルのビルドを行い、実際にPythonから呼び出し可能な拡張モジュールを生成します。これを以下のコマンドで行いました。
python -m numpy.f2py -c svd_module.pyf dsvdc.f90このビルドプロセスでは、f2pyが以下の処理を自動実行します。
Cラッパーコード生成:
.pyfファイルのインターフェース定義に基づいて、PythonのC APIを使用するラッパーコード(svd_modulemodule.c)を生成します。このコードがPythonオブジェクトとFortranのデータ型の相互変換を担当します。Fortranラッパーコード生成(必要に応じて):形状引継ぎ配列や派生型などの高度なFortran機能を使用している場合は、追加のFortranラッパーコード(
svd_module-f2pywrappers.f)も生成されます。コンパイル:(a) Fortranコンパイラを使用してFortranソースコード(
dsvdc.f90)をオブジェクトファイルにコンパイル。(b) Cコンパイラを使用してCラッパーコードをオブジェクトファイルにコンパイル。(c) 必要に応じてFortranラッパーコードもコンパイルリンク:コンパイルされたオブジェクトファイルを、Python C API、NumPy C API、Fortranランタイムライブラリとリンクして、Python拡張モジュールを作成します。このリンク処理により、生成されるモジュールは特定のPythonやNumPyのバージョンに依存することになります。
ビルドが完了すると、実行環境に応じた拡張モジュールが生成されます。Windowsでは.pyd、LinuxやMacでは.soという拡張子のファイルになります。
今回はWindowsで作業したため、svd_module.cp312-win_amd64.pydというファイルが作成されました。このファイルはPythonの拡張モジュールであり、通常のPythonモジュールと同じようにimport svd_moduleでインポートして利用できるものです。
生成されたインターフェースの確認
ビルドしたモジュールが正しく動作し、意図したインターフェースを提供しているか確認します。 Pythonオブジェクトが持つドキュメント文字列(doc)を表示することで、f2pyが生成した関数の仕様を手軽に確認できます。
ドキュメント文字列の確認
> python -c "import svd_module; print(svd_module.svd.dsvdc.__doc__)"
info = dsvdc(x,n,p,s,e,u,v,job)
Wrapper for ``dsvdc``.
Parameters
----------
x : in/output rank-2 array('d') with bounds (f2py_x_d0,f2py_x_d1)
n : input int
p : input int
s : in/output rank-1 array('d') with bounds (f2py_s_d0)
e : in/output rank-1 array('d') with bounds (f2py_e_d0)
u : in/output rank-2 array('d') with bounds (f2py_u_d0,f2py_u_d1)
v : in/output rank-2 array('d') with bounds (f2py_v_d0,f2py_v_d1)
job : input int
Returns
-------
info : intこの出力からinfoのみが戻り値となり、出力用の配列s,
e, u,
vはin/output(入出力)引数として扱われていることが確認できました。これは意図したとおりの動作です。
実行と検証
最後に、生成されたモジュールの動作確認を行いました。
指定されたデータファイルから行列を読み込み、dsvdcを呼び出して実行時間を測定する以下のようなコード(抜粋)で、オリジナルのFortranプログラムと計算結果および実行性能を比較しました。
import svd_module
import numpy as np
# ファイルからxにデータを読み込む
x, n, p = get_matrix_from_file(data_file)
job = 11
s = np.zeros(p, dtype=float)
e = np.zeros(p, dtype=float)
u = np.zeros((n, n), dtype=float, order='F') # Fortran互換のため列優先で確保
v = np.zeros((p, p), dtype=float, order='F') # Fortran互換のため列優先で確保
start_time = time.perf_counter() # 開始時間の記録
info = svd_module.dsvdc(x, n, p, s, e, u, v, job)
end_time = time.perf_counter() # 終了時間の記録
# (結果表示処理等 ... )このコードを、オリジナルのFortranプログラムと同じテストデータで実行し、結果を比較しました。
f2py版の実行結果
> python benchmark_svd_python_f2py.py matrix_1600x1600_rand_uniform.bin
13.46623840 # 実行時間(秒)
Top 5 singular values (Python f2py):
23.007873050107914 22.898887126396772 ...
First 3 components of leading eigenvector (1st column of U):
0.015510246530786 0.042426665711607 0.010966853963481オリジナルFortran版の実行結果
> benchmark_svd_fortran_original.exe matrix_1600x1600_rand_uniform.bin
13.73400021 # 実行時間(秒)
Top 5 singular values (Fortran Original):
23.007873050107914 22.898887126396772 ...
First 3 components of leading eigenvector (1st column of U):
0.015510246530786 0.042426665711607 0.010966853963481f2py版とオリジナルのFortran版で、計算結果(特異値、固有ベクトル)は完全に一致しました。また、実行時間も同等の範囲内であることが確認できました。
異なるインターフェースへの簡単な切り替え
前述のとおり.pyfファイルを利用するメリットは、Fortranコードを変更せずにPython側のインターフェースを柔軟に変更できる点にあります。
この柔軟性を実際に確認するため、出力配列 s, e, u, v
をPython関数の戻り値として受け取るインターフェースへの変更を行ってみました。
つまり
s, e, u, v, info = svd_module.dsvdc(x, n, p, job)のようなパターンです。
具体的には.pyfファイルに以下の変更を適用しました。
変更点
real(kind=8) dimension(:),intent(inout) :: s
real(kind=8) dimension(:),intent(inout) :: e
real(kind=8) dimension(:,:),intent(inout) :: u
real(kind=8) dimension(:,:),intent(inout) :: v を以下のように変更しました:
real(kind=8) dimension(p),intent(out) :: s
real(kind=8) dimension(p),intent(out) :: e
real(kind=8) dimension(n,n),intent(out) :: u
real(kind=8) dimension(p,p),intent(out) :: v s, e, u, v
の属性をintent(out)に変更すると同時に、配列サイズも明示的に指定しています。これはintent(out)の場合、f2pyが戻り値用の配列を適切なサイズで確保する必要があり、そのためにサイズを明確に示す必要があるためです。
(注: u のサイズは f2py の仕様上、job
の値に応じて動的に変更することが難しいため、すべてのjobの値に対応できるよう
n 行 n 列で確保しています。s のサイズもこれに倣い、厳密な min(n + 1, p)
ではなく安全かつシンプルな p を採用しています。)
これらの変更により、infoに加えてs,
e, u,
vも戻り値となるインタフェースが実現できます。
この変更を反映したpyfファイルを、先ほどと同じコマンドでビルドしました。
python -m numpy.f2py -c svd_module.pyf dsvdc.f90念のため、ドキュメント文字列を出力し、意図したとおりとなっていることを確認しました。
> python -c "import svd_module; print(svd_module.svd.dsvdc.__doc__)"
s,e,u,v,info = dsvdc(x,n,p,job)
Wrapper for ``dsvdc``.
Parameters
----------
x : in/output rank-2 array('d') with bounds (f2py_x_d0,f2py_x_d1)
n : input int
p : input int
job : input int
Returns
-------
s : rank-1 array('d') with bounds (p)
e : rank-1 array('d') with bounds (p)
u : rank-2 array('d') with bounds (n,n)
v : rank-2 array('d') with bounds (p,p)
info : int次に、呼び出し側のPythonコードを上記仕様に合わせて変更し、実行したところ、同じ結果が得られ、パフォーマンスも同等でした。
仕様に合わせた呼び出し側Pythonコード
import svd_module
import numpy as np
# ファイルからxにデータを読み込む
x, n, p = get_matrix_from_file(data_file)
job = 11
start_time = time.perf_counter() # 開始時間の記録
s, e, u, v, info = svd_module.dsvdc(x, n, p, job) # s, e, u, vも受け取る形での呼び出し
end_time = time.perf_counter() # 終了時間の記録
# (結果表示処理等 ... )実行結果
> python benchmark_svd_python_f2py_intent_out.py matrix_1600x1600_rand_uniform.bin
13.58452720 # 実行時間(秒)
Top 5 singular values (Python f2py):
23.007873050107914 22.898887126396772 ...
First 3 components of leading eigenvector (1st column of U):
0.015510246530786 0.042426665711607 0.010966853963481このように、.pyfファイルを経由する方法は、Fortranオリジナルコードに触らずに、.pyfファイルをカスタマイズすることで、Python側の呼び出し方を自由に変更できるというメリットがあります。
!f2pyディレクティブを利用する方法
.pyfファイルを介さず、Fortranソースコードからより直接的に拡張モジュールをビルドする方法もあります。これは!f2pyディレクティブと呼ばれる特殊なコメントをソースコードに追記することで実現できます。これらのディレクティブはFortranコンパイラからは通常のコメントとして扱われるため、Fortran側の動作には一切影響しません。
この方法でも、インターフェース定義ファイルを経由する方法で可能な、主要なカスタマイズに多く対応していますが、この方法では.pyfファイルの生成・編集という中間ステップを省略でき、インターフェース定義がFortranソースコード内に埋め込まれるため、別ファイルとして.pyfを管理する必要がなくなります。
!f2pyディレクティブの記述
ここでは、インターフェース定義ファイルを経由する方法で.pyfファイルを使って定義した時のインターフェースと同じになるように、すべての引数の役割を!f2pyディレクティブで明示的に定義しました。具体的な指定内容は以下の通りです。
- 入出力 (
inout):x, s, e, u, vに対して指定。 - 入力 (
in):n, p, jobに対して指定。 - 出力 (
out):infoに対して指定。 - パラメータ定義: 倍精度実数で用いるパラメータ
dpの値を明示的に定義。
これらのディレクティブを追記したソースコードは以下のようになります。
!f2pyディレクティブを追記したソース
(dsvdc_quicksmart.f90)
SUBROUTINE dsvdc(x, n, p, s, e, u, v, job, info)
INTEGER, INTENT(IN) :: n
INTEGER, INTENT(IN) :: p
REAL (dp), INTENT(IN OUT) :: x(:,:)
REAL (dp), INTENT(IN OUT) :: s(:)
REAL (dp), INTENT(IN OUT) :: e(:)
REAL (dp), INTENT(IN OUT) :: u(:,:)
REAL (dp), INTENT(IN OUT) :: v(:,:)
INTEGER, INTENT(IN) :: job
INTEGER, INTENT(OUT) :: info
! 以下がf2pyへの指示文
!f2py integer, parameter :: dp = 8
!f2py intent(inout) :: x, s, e, u, v
!f2py intent(in) :: n, p, job
!f2py intent(out) :: infoビルドプロセス
ディレクティブを埋め込んだソースファイルは、以下に示すようにコマンド1つで.pyfを介さずに直接Pythonモジュールをビルドできます。
python -m numpy.f2py -c dsvdc_quicksmart.f90 -m svd_module only: dsvdcこのコマンド一つで、Fortranコードとディレクティブの情報から.pydファイル(LinuxやMacでは.so)が直接生成されます。
このように!f2pyディレクティブを使う方法は、.pyfファイルの生成・編集という中間ステップを省略でき、インターフェース定義をソースコード内で一元管理できるというメリットがあります。
しかし、その一方で、この方法ではFortranソースコードへの!f2pyディレクティブの追加が必要となります。これはFortranの動作には影響しないコメントですが、オリジナルのソースコードを変更することになります。
これに対して.pyfファイルを経由する方法では、Fortranコードを一切変更せずにPythonインターフェースをカスタマイズできます。
オリジナルのコードを変更できない場合や、複数ファイルのルーチンを一つのモジュールにまとめるような高度なカスタマイズが必要な場合は、.pyfファイル方式の方が適しています。
f2pyの実用上の課題
前述のとおり、f2pyはFortranコードをPythonから利用するための有効な手段ですが、実際の運用においては以下のような実用上の課題が存在します。
1. 環境構築の複雑さ
f2pyを使い始める際の最初のハードルは、動作環境の準備です。
本稿で示した python -m numpy.f2py -c ...
等のコマンドを実行するためには、背後で動作するFortranコンパイラ、Cコンパイラ、リンカがすべて正しく機能している必要があります。
具体的には、以下の準備作業がまず必要となります:
- 各コンパイラのインストール
- 環境変数PATHの設定
- 各ツール間のバージョン整合性の確認
特に複数のコンパイラがインストールされている環境では、PATHの優先順位により意図しないコンパイラが選択される、あるいは互換性のないリンカが優先的に選ばれてしまう等の問題に遭遇することがあります。このような問題は使用するPCの状況(インストールされているコンパイラやリンカ、PATHの順番等)に依存するものであり、既存の環境との整合性を保ちながら解決しなければならないので、時間がかかる事も少なくありません。また、Windows環境では、MinGW、MSYS2、Visual Studioなどツールの選択肢が多く、それぞれの設定方法が異なるため、環境の構築は更に複雑になります。実際、公式ドキュメントでも「WindowsでのF2PYサポートはLinuxと同等ではない」と明記されています。
本稿の執筆にあたっても、動作環境の構築には数時間を費やしました。
2. バージョン依存と再ビルドの負担
f2pyで生成した拡張モジュール(.soや.pydファイル)は、実行環境が少しでも変わると動作しなくなることが多く、そのたびに再ビルドが必要となることが継続的なメンテナンスの負担となります。
これは、f2pyにより生成されるモジュールが以下の3つのコンポーネントと密接に結びついているためです。
- Pythonバージョン (CPython API)
- NumPyバージョン (NumPy C API)
- コンパイラランタイム
最も影響が大きいのはCPython APIへの依存です。f2pyが生成するモジュールはPython C APIを通じてPythonインタプリタと通信しますが、このAPIはメジャーバージョンだけでなく、マイナーバージョン間(例: Python 3.12から3.13)でも互換性が保証されていません。そのため、Pythonをアップデートすると、それまで使えていた拡張モジュールはAPIの不整合で動かなくなり、再ビルドが必須となります。
拡張モジュールはビルド時のNumPy C APIにも依存していますが、こちらは通常のバージョンアップでは多くの場合、問題にはなりません。ただし、NumPy 2.0のような大規模アップデートでは互換性が失われ、再ビルドが必要になることもあります。
また、コンパイラのランタイムライブラリへの依存についても、通常のシステムアップデートの範囲内であれば互換性が保たれていることが多く、問題となるケースは比較的稀です。
このようなバージョン依存性(特にCPython APIへの依存)により、環境が変わるたびに再ビルドが必要となることが、f2pyを継続的に利用する上での大きなメンテナンス上の負担となります。
まとめと次回予告
f2pyは、既存のFortranコードをPythonから使えるようにするための効率的で強力なツールですが、その利便性は複雑な環境構築、頻繁な再ビルドの必要性などと引き換えになります。
このため、外部ツールへの依存を極力減らし、より透明性が高く、長期的に安定した連携方法も求められます。
次回、第6回「ctypesとbind(C)によるFortranコードのラッピング」では、この課題に対する一つの答えとして、Fortran
2003標準のbind(C)機能とPython標準モジュールであるctypesを組み合わせた、外部ツールに依存しない連携手法を取り上げます。