
第1回では、移行対象のFortranコード dsvdc.f90
を分析し、Pythonへの移行における主な技術的課題として「GOTO文による複雑な制御フロー」と「1ベースの配列インデックス」を特定しました。
これらの課題を残したままのコードをPythonに移植しようとすると作業が複雑になり、バグの混入リスクも高まります。
そこで今回は、Pythonへの移植を本格的に開始する前に、まずはFortranコード自体を改善(リファクタリング)します。この事前準備の目的は、GOTO文の解消やインデックスの調整といった問題を先にFortran側で解決し、Pythonへの移植作業に集中できるようにすることです。

特にGOTO文はPythonに同等の機能がないため、この段階で解消しておく必要があります。一方、配列を0ベースインデックスに変換する作業は、Pythonへの移植と同時に進めることも可能ですが、複雑な書き換え作業の最中にインデックス調整まで並行して行うのは得策ではありません。
このような背景から、今回のリファクタリングは以下の2段階で進めました。
- フェーズ1:GOTO文の構造化
- フェーズ2:0ベースインデックス化
Pythonへの移植前にこれらの作業をFortran側で実施するメリットの一つは、元のコードに対して「少し変更してはテストする」というサイクルを安全に繰り返せる点です。 これにより、大規模な変更を一気に行うリスクを避け、着実に作業を進めることができます。
フェーズ1:GOTO文の構造化
このフェーズではコードに含まれているすべてのGOTO文を取り除きます。
ここでの作業は、動作を保つために連動して変更する必要がある部分をまとめて修正し、その完了時点でテストを実施して元のコードと同じ振る舞いをするかどうか確認しながら進めました。
分岐処理の構造化
まず、サブルーチン内に点在する前方ジャンプのGOTO文を、同等のIF-THEN-ELSEブロックに置き換えていきました。単純な処理のスキップから、複数のジャンプが絡み合う複雑な箇所まで、体系的に構造化していきました。
修正例1:条件による処理スキップの構造化
特定の条件で処理をスキップする前方ジャンプを、IFブロックで囲む形に修正しました。
構造化前
IF (lu < 1) GO TO 170
DO l = 1, lu
...
END DO
170 m = MIN(p,n+1)構造化後
IF (lu >= 1) THEN
DO l = 1, lu
...
END DO
END IF
m = MIN(p,n+1)修正例2:より複雑な分岐構造の整理 複数のGOTO文と文番号が絡み合う制御フローは、ネストしたIF-THEN-ELSE構造に再構成しました
修正前
DO ll = 1, nct
l = nct - ll + 1
IF (s(l) == 0.0D0) GO TO 250
lp1 = l + 1
IF (ncu < lp1) GO TO 220
DO j = lp1, ncu
t = -DOT_PRODUCT(u(l:n,l), u(l:n,j)) / u(l,l)
u(l:n,j) = u(l:n,j) + t * u(l:n,l)
END DO
220 u(l:n,l) = -u(l:n,l)
u(l,l) = 1.0D0 + u(l,l)
lm1 = l - 1
IF (lm1 < 1) CYCLE
u(1:lm1,l) = 0.0_dp
CYCLE
250 u(1:n,l) = 0.0_dp
u(l,l) = 1.0_dp
END DO修正後
DO ll = 1, nct
l = nct - ll + 1
IF (s(l) /= 0.0D0) THEN
lp1 = l + 1
IF (ncu >= lp1) THEN
DO j = lp1, ncu
t = -DOT_PRODUCT(u(l:n,l), u(l:n,j)) / u(l,l)
u(l:n,j) = u(l:n,j) + t * u(l:n,l)
END DO
END IF
u(l:n,l) = -u(l:n,l)
u(l,l) = 1.0D0 + u(l,l)
lm1 = l - 1
IF (lm1 >= 1) THEN
u(1:lm1,l) = 0.0_dp
END IF
ELSE
u(1:n,l) = 0.0_dp
u(l,l) = 1.0_dp
END IF
END DOこのようにして、比較的単純なものから、より複雑なものへ順次構造化を進めました。
複雑なメインループの構造化
サブルーチンdsvdcの最も主要な計算部分に、後方ジャンプ(ループ処理)と複数の前方ジャンプ(ループからの脱出)が混在する、複雑なGOTO文のフローがありました。このメインループの構造化も、以下の手順で段階的に進めました:
- 分岐ロジックの整理:
kase変数の値に応じた分岐をSELECT CASE文に集約し、処理の流れを明確化しました。 - ループ構造の明確化:
メインロジック全体を一つの
DOループで囲みました。そして、ループの先頭に戻る後方ジャンプをCYCLE文へ、ループから脱出する前方ジャンプをEXIT文へ置き換えました。
修正前のメインループ構造(一部):
360 IF (m == 0) GO TO 620
...
SELECT CASE ( kase )
CASE ( 1 )
GO TO 490
...
END SELECT
490 ...
GO TO 610
...
610 GO TO 360
620 RETURN修正後のメインループ構造:
DO
IF (m == 0) THEN
EXIT
END IF
...
SELECT CASE ( kase )
CASE ( 1 )
...
CYCLE
...
END SELECT
End Do以上のような段階的な作業を通じて、元のコードの動作を維持したままGOTO文を完全に除去しました。
フェーズ2:配列インデックスの0ベース化
次のフェーズではFortranの1ベースの配列インデックスを、Python/NumPyの0ベースのインデックスに変更します。配列宣言で下限を明示的に0と指定し、配列にアクセスするすべての箇所のインデックスを調整します。
変更例:
! 変更前(1ベース)
REAL :: x(10) ! 一般的な配列宣言:インデックスは 1, 2, ..., 10
...
print *, x(2), x(8)! 変更後(0ベース)
REAL :: x(0:9) ! 下限0を明示した配列宣言:インデックスは 0, 1, ..., 9
...
print *, x(1), x(7) ! インデックスを1つずつ減算
上記はシンプルな例ですが、実際のコードでのインデックス調整は慎重に行う必要があります。配列が広範囲で参照されている場合、一度にすべてを修正するのはリスクが高いため、このフェーズでも段階的なアプローチを採用しました。
ポインタ再マッピングによる段階的リファクタリング
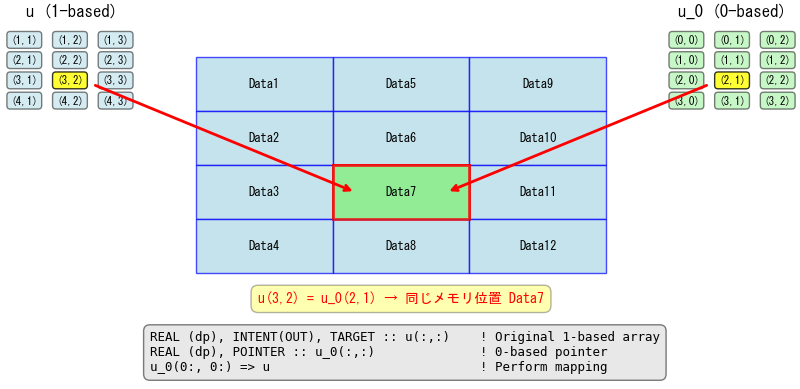
配列のインデックスを1ベースから0ベースへ変更する「0ベース化」を行う方法の一つに、Fortranのポインタ再マッピング機能の利用があります。この機能は、既存の1ベース配列が使用しているメモリ領域はそのままに、インデックスの開始番号のみを0に変更した「ビュー(view)」(別名)として機能するポインタ変数を作成するものです。
ポインタ再マッピングの概念:
! 元の1ベース配列 (仮引数にTARGET属性を付与)
REAL (dp), INTENT(OUT), TARGET :: u(:,:)
! 0ベースのビューとなるポインタを宣言
REAL (dp), POINTER :: u_0(:,:)
! マッピング実行 (u_0 は u と同じメモリを指す0ベースのエイリアスとなる)
u_0(0:, 0:) => uこのアプローチの特徴は、元の1ベース配列 (u) と0ベースのビュー (u_0) が、物理的に同じメモリを指す点にあります。例えばu(3,2)とu_0(2,1)は同じメモリ位置を示します。この特性により、コード内で1ベースのアクセスと0ベースのアクセスを一時的に共存させることが可能です。そのため、コード全体を一括で書き換えるのではなく、部分的に0ベース化を進め、その都度テストで動作確認を行う、段階的なリファクタリングが可能となります。
実際の作業は、配列を順番に一つずつ対象とし、さらにその中でも「一つのループ」や「一つの計算ブロック」といった論理的な単位で進めます。例えば、配列 s を0ベース化する手順は以下の通りです。
- 配列 s を指す0ベースのポインタ s_0 を用意します。
- サブルーチン内で s が使用されているループや計算ブロックを一つ選び、その範囲内に限定して、s へのアクセスをすべて s_0 を用いた形式に書き換えます。この時点では、書き換えた範囲の外では、既存の1ベースの s がそのまま使用されます。
- コードをコンパイル・実行し、リファクタリング前と計算結果が変わらないことを確認します。
- 動作に問題がなければ、次のループや処理ブロックへ進み、同様の書き換えとテストを繰り返します。
- このサイクルを繰り返し、サブルーチン内の s がすべて s_0 に置き換わったら、e や x といった他の配列に対しても同じ手順を適用します。
- すべての対象配列の0ベース化が完了したら、エディタの置換機能などを用いてポインタ名(例: s_0)を元の配列名(s)に一括で戻します。その後、サブルーチンの引数宣言を REAL :: s(0:) のように0ベースの配列として定義し直し、不要になったポインタ変数の宣言とマッピングのコードを削除することで、段階的なリファクタリングが完了します。
その他のアプローチ(参考情報)
今回は採用しませんでしたが、ポインタ再マッピングが適用できない場合(例えば大きさ引継ぎ配列の場合など)の代替手法として、インデックス変換用のラッパー関数を使う方法もあります。
この手法では、0ベースのインデックスを1ベースに変換する関数を定義し、配列アクセス時に介在させます:
INTEGER FUNCTION _ZB(zero_based_index)
_ZB = zero_based_index + 1
END FUNCTION例えば、x(i) のような1ベースの配列アクセスを
x(_ZB(i-1))
という形に書き換えます。これにより、_ZB()
の括弧内では0ベースのインデックス (i-1)
を使いながら、_ZB関数がそれを1ベースの値に変換するため、既存の配列に正しくアクセスできます。
この手法もポインタ再マッピングと同様に、段階的にリファクタリングを進められる
方法です。コードの一部を _ZB
を使った形式に書き換えても、プログラム全体の動作は変わりません。そのため、「少し修正してはテストする」という安全なサイクルで作業を進めることができます。
そして、すべての配列アクセスを _ZB
形式に統一した後、最終的なプロセスとして、エディタの置換機能などを使って
_ZB の関数呼び出しを外します(例: _ZB(i-1) を
i-1
に変更)。同時に、配列宣言を0ベースの形式(例:X(10) を
X(0:9))に修正すれば、安全に0ベースへの移行が完了します。
この方法は配列の種類に依らず適用できる利点があります。
変換後のインターフェース
(dsvdcの最終形):
SUBROUTINE dsvdc(x, n, p, s, e, u, v, job, info)
IMPLICIT NONE
INTEGER, INTENT(IN) :: n, p, job
REAL (dp), INTENT(INOUT) :: x(0:,0:)
REAL (dp), INTENT(OUT) :: s(0:), e(0:), u(0:,0:), v(0:,0:)
INTEGER, INTENT(OUT) :: info
...今回の0ベース化の作業により、変換後のインターフェースもこのように0ベースになっています。
リファクタリング済みコード
リファクタリング済のコードは以下からご確認いただけます。
まとめと次回予告
今回のリファクタリングでは dsvdc.f90
を修正し、Pythonへの移植を妨げる要因を取り除きました。結果として、可読性が向上し、より現代的なFortranコードになっています。
主な変更点は以下の2点です。
GOTO文を削除し、制御フローを構造化しました。- 配列のインデックスを、Pythonと同じ0ベースに統一しました。
これらの変更により、移植作業はロジックの再設計といった手間のかかる作業から、より機械的な構文の置き換えへと変わります。結果として作業プロセスが明確になり、人的なミスが入り込む余地を減らすことにつながります。
次回、第3回「Pythonへの逐次移植とパフォーマンスの問題」では、このFortranコードをPythonへ1対1で移植するプロセスを見ていきます。また、その際に明らかになるパフォーマンス上の課題についても検証します。