
本シリーズでは、実際のFortranコードを題材として、Python化の様々なアプローチを実践的に検証していきます。
シリーズ全体で使用する題材コード
今回取り上げるのは、 Alan Miller氏のソフトウェアコレクションで公開されている、特異値分解(SVD)を行うFortranサブルーチン dsvdc.f90 です。 GOTO文を含む数値計算コードという、Fortranらしい典型的な特徴を持ちつつ、適度な規模であることから、本シリーズの題材として選択しました。
dsvdc.f90 の概要と特徴
dsvdc.f90
は、線形計算ライブラリLINPACKのDSVDCを起源とするSVDサブルーチンです。Alan
Miller氏によってFortran
90形式に更新されており、以下の点が特徴となっています。
- 現代的なFortran構文の採用:
自由形式、
IMPLICIT NONEによる暗黙の型宣言の禁止、関連サブルーチンのMODULE化など、現代的なFortranの記述スタイルが取り入れられています。 GOTO文の残存: しかし、プログラムの制御フローには旧来のFORTRAN 77で一般的だったGOTO文による分岐が多く残されており、完全に現代化されたわけではない点が見て取れます。
コードの構造
dsvdc.f90 は約600行のコードで、SVD
という単一のモジュール内に以下の4つのサブルーチンが定義されています。
dsvdc.f90
MODULE SVD
IMPLICIT NONE
INTEGER, PARAMETER :: dp = SELECTED_REAL_KIND(12, 60)
CONTAINS
SUBROUTINE drotg(da, db, dc, ds)
END SUBROUTINE drotg
SUBROUTINE dswap1(n, dx, dy)
END SUBROUTINE dswap1
SUBROUTINE drot1(n, dx, dy, c, s)
END SUBROUTINE drot1
SUBROUTINE dsvdc(x, n, p, s, e, u, v, job, info)
END SUBROUTINE dsvdc
END MODULE SVDコードの呼び出し構造の分析
nAG Fortranコンパイラのコールグラフ生成ツールを使い、サブルーチン間の呼び出し関係を調査しました。
コールグラフ
1: DSVDC
2: DROTG
3: DROT1
4: DSWAP1
呼び出しテーブル
手続 呼び出し元
DROT1 DSVDC, in module SVD
DROTG DSVDC, in module SVD
DSVDC 無し
DSWAP1 DSVDC, in module SVD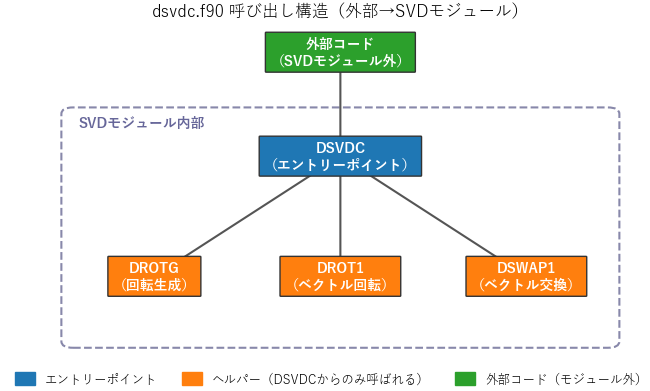
この解析結果から、コードの構造は比較的シンプルであることがわかります。
DSVDCがメインのサブルーチンであり、内部でDROTG、DROT1、DSWAP1の3つを呼び出しています。- これら3つのサブルーチンは
DSVDC専用のヘルパー関数として機能し、他からは呼び出されません。 - そして
DSVDC自体を呼び出すコードが他に存在しないことから、これが外部から利用される「エントリーポイント」として設計されていることが読み取れます。
したがって、Pythonへの移植や連携を行う上での最初のステップは、このDSVDCのインターフェース仕様を正確に把握することになります。
インターフェース仕様の確認
dsvdcサブルーチンのインターフェース(引数の仕様)は以下の通りです。
SUBROUTINE dsvdc(x, n, p, s, e, u, v, job, info)
IMPLICIT NONE
INTEGER, INTENT(IN) :: n, p, job
REAL (dp), INTENT(IN OUT) :: x(:,:)
REAL (dp), INTENT(OUT) :: s(:), e(:), u(:,:), v(:,:)
INTEGER, INTENT(OUT) :: infoこの定義から、以下のことが分かります。
データ型:
REAL(dp)という記述と、モジュール冒頭のdp = SELECTED_REAL_KIND(12, 60)という定義から、x、s、e、u、v の各配列引数が倍精度実数であることがわかります。引数の役割:
INTENT属性が明示されているので、各引数が入力(IN)、出力(OUT)、入出力(IN OUT)のいずれであるかがわかります。サブルーチン形式: このプログラムは
FUNCTION(関数)ではなくSUBROUTINE(サブルーチン)として定義されています。戻り値はなく、計算結果はすべて引数経由で渡されます。Pythonにはサブルーチンがなく、すべてが関数として実装されるため、この違いは意識しておき、移植の際に、このサブルーチンをどのようなPython関数として実装するか、例えば主要な結果やステータスを戻り値とするのか、あるいはFortranの形式に倣って引数で処理を完結させるのか、といった設計上の判断が必要になります。1から始まる配列: Fortranでは、配列の下限を明示的に指定しない限り、デフォルトで1から始まります。上記のインターフェース定義では
x(:,:)のように下限が省略されているため、配列のインデックスは通常どおり1から始まる方式(1ベースインデックス)であることがわかります。これは、0から始まるPython(0ベースインデックス)へ移植する際に注意すべき点です。
宣言部分を見るだけでも多くの情報が得られますが、x(:,:)
のような形状引継ぎ配列の場合、具体的に期待される配列サイズの情報が得られないこともあります。このような場合、配列の正確なサイズを特定する必要があります。
本コードでは幸い、引数に関するコメントが詳しく記述されていたため、その情報から各配列に期待されるサイズを知ることができました。
| 引数 | 期待されるサイズ |
|---|---|
x(:,:) |
n 行 p 列 |
s(:) |
min(n + 1, p) |
e(:) |
p |
u(:,:) |
n 行、列数は job
引数に依存 (n または min(n, p)) |
v(:,:) |
p 行 p 列 |
しかし、コメントや関連ドキュメントが無いような場合は、呼び出し元のコードも参考にしつつ、サブルーチン内での変数の使用パターンを調査してサイズを特定する必要があります。
例えばxのサイズを特定する場合、xがアクセスされているコード部分を探してその使われ方を調査します。
! ...
Do j = lp1, p
! ...
t = -dot_product(x(l:n,l), x(l:n,j))/x(l, l)
x(l:n, j) = x(l:n, j) + t*x(l:n, l)
End Doここでは x(l:n, ...)
というスライス構文から、配列の第1添え字(行)が最大で引数
n
までアクセスされることが読み取れます。同様に、Do j = lp1, p
のループでは、ループ変数 j が
x(..., j)
のように配列の第2添え字(列)として使われ、その上限が
p であることがわかります。 これらの情報から、配列
x が n 行 p
列であろうと判断できます。
以上の分析により、エントリーポイントである DSVDC を外部から利用するための技術仕様(データ型、引数の役割、各配列の正確なサイズなど)が明らかになりました。 この情報は、この後に行うPythonへの書き換え、Numpyによるベクトル化、Numbaでの高速化、あるいはf2pyやBind(C)を用いたラッパー作成といった、今後の作業の基礎となります。
Python化の課題1:GOTO文による複雑な制御フロー
前述のとおり、このコードには旧来のFORTRAN 77で一般的だったGOTO文による分岐が多く残されています。調査したところ、GOTO文は全部で43箇所で使われており、シンプルな処理フローを形成している場合もあれば、より複雑に絡み合った構造になっている場合もありました。
【シンプルな条件分岐の例】
例えば、drotgサブルーチンでは、IF文の結果に応じて処理をスキップするという、比較的分かりやすいGOTOの使い方をしています。
IF (ABS(da) <= ABS(db)) GO TO 10
! 条件1: ABS(da) > ABS(db) の場合
...
RETURN
10 IF (db == 0.d0) GO TO 20
! 条件2: ABS(da) <= ABS(db) かつ db /= 0 の場合
...
RETURN
20 ! 条件3: ABS(da) <= ABS(db) かつ db == 0 の場合
...
RETURNこのような前方への単純なジャンプで構成された処理フローは理解しやすく、現代的な構造化プログラミングの書き方に簡単に置き換えられます。(以下、置き換え例)
【構造化したコード例】
IF (ABS(da) > ABS(db)) THEN
! 条件1: ABS(da) > ABS(db) の場合
ELSE IF (db /= 0.0d0) THEN
! 条件2: ABS(da) <= ABS(db) かつ db /= 0 の場合
ELSE
! 条件3: ABS(da) <= ABS(db) かつ db == 0 の場合
END IF【より複雑な分岐の例】
一方で、dsvdcサブルーチンの中心部には、GOTO文が複雑に組み合わさった大きなループ構造があります。
! ループ開始点
360 IF (m == 0) GO TO 620 ! ループの終了条件
! ... (中略) ...
IF (iter < maxit) GO TO 370
info = m
GO TO 620 ! 最大繰り返し回数を超えたら終了
! ... (GOTOを用いた複雑な条件分岐) ...
480 l = l + 1
SELECT CASE ( kase )
CASE ( 1); GO TO 490
CASE ( 2); GO TO 520
CASE ( 3); GO TO 540
CASE ( 4); GO TO 570
END SELECT
! ... (各ケースの処理ブロック) ...
! 次のループへ
610 GO TO 360
! 処理の終了点
620 RETURNこの部分では、GO TO 360という後方へのジャンプでループを形成しつつ、GO TO 620でループから脱出し、さらにSELECT CASEの結果に応じてGO TO 490のように様々な場所に処理が飛ぶ構造になっています。そのため、コードを上から順に追うだけでは全体の処理の流れを理解することが困難です。
PythonにはGOTO文に相当する構文が存在しないため、こうした制御フローの構造化は、Python化において最初に解決すべき課題です。
Python化の課題2:1ベースの配列インデックス
FortranからPythonへコードを移植する際、配列のインデックスの違いに特に注意が必要です。Fortranでは配列のインデックスが1から始まるのが標準ですが、Python(NumPy配列など)では0から始まります。この違いを意識しないと、インデックス値が1ずれることによる配列範囲外アクセスや意図しない要素の参照などの不具合が発生します。
単純な配列要素の参照であれば、Fortranの A(i, j) をPythonで A[i-1, j-1] のように機械的に変換することができます。しかし、実際の数値計算コードでは、以下のような状況でこの変換が複雑になります。
- 複雑なインデックス計算:配列のインデックスが、変数や定数を含む数式で決まる場合、-1のオフセットをどこでどう調整すべきか、その把握と適切な変換が難しくなります。
- 部分配列(スライス)の取り扱い:Fortranの
A(i:j)は終点のjを含むj-i+1個の要素を指します。一方、PythonのA[i:j]は終点のjを含まないj-i個の要素を指します。例えばFortranのA(3:5)は3~5番目の3要素を示しますが、PythonのA[3:5]は4~5番目の2要素のみです。この点も誤りが発生しやすいポイントです。

一つの例としてdsvdc サブルーチンの終盤付近にあるループを構造を示します。
200 DO ll = 1, nct
l = nct - ll + 1 ! (1) ループ変数 ll からインデックス l を計算
IF (s(l) == 0.0D0) GO TO 250
lp1 = l + 1
IF (ncu < lp1) GO TO 220
DO j = lp1, ncu
t = -DOT_PRODUCT(u(l:n,l), u(l:n,j)) / u(l,l)
u(l:n,j) = u(l:n,j) + t * u(l:n,l)
END DOここでは、まず(1)の l = nct - ll + 1
という計算で、ループ変数 ll から実際の配列インデックス
l を求めています。その後の処理では、この l
を使って配列 s や u
を参照しています。さらに配列 u
へのアクセスでは部分配列(スライス)も使われており、この点がPythonへの変換をより複雑にしています。
このように、インデックスの基準の違いへの対応は、注意深く行う必要があるものです。
ほとんどのFortranコードは1ベースで記述されているため、インデックスの変換は、Pythonへ移植する際に避けて通れない課題です。
補足:メモリレイアウトについて
Fortranは、多次元配列をメモリ上に配置する際に列優先(Column-major)順序を用います。このコードも、多くの数値計算コードと同様に、列優先のメモリレイアウトを前提として最適化されています。 一方、Python(NumPy)は行優先(Row-major)を標準としています。行優先への変更には、ループ構造の大幅な修正が必要で、手間とリスクが伴います。そこで今回は、NumPyのorder=’F’オプションを使ってPython側でもFortran互換のメモリレイアウトを用いるようにし、既存のアクセスパターンをそのまま活用しつつ性能は維持する方針としました。
まとめと次回の方針
今回は、移植対象のFortranコードdsvdc.f90の構造とインターフェース仕様を確認しました。
その結果、単一のMODULE構造や明確なINTENT属性といった移植に適したいくつかの特徴が確認できた一方で、GOTO文を多用した複雑な制御フローや1ベースの配列インデックスといった、対処すべき技術的な課題が浮き彫りになりました。
次回は、これらの課題に対処するため、まずFortranコードのリファクタリングを行い、GOTO文の削減と配列インデックスの0ベース化を進めることで、よりPythonへ移植しやすい形に整えていきます。