
これまで6回にわたって、Fortranで書かれた数値計算コードを現代のPythonエコシステムで活用するための具体的なアプローチを探ってきました。シリーズ最終回となる今回は、これまでの検証結果を総括し、皆さんがそれぞれの状況に最適な手法を選択できるよう、判断材料となる情報をお届けします。
シリーズの振り返り
本シリーズでは、既存のFortran資産をどのように扱うべきかという課題に対して、大きく2つの方針を設定し、検証を進めてきました。
方針A:すべてをPythonへ書き換える「完全移行」 Fortranへの依存から完全に脱却し、開発体制をPython中心に刷新することを目指すアプローチです。
方針B:互いの長所を活かす「ハイブリッド連携」 実績あるFortranの高速な計算ルーチンはそのまま活用し、Pythonから「計算部品」として呼び出すアプローチです。
これらの方針をもとに、以下の5つの具体的な実装アプローチを実際に試し、それぞれの特性を詳しく検証してきました。
- ① 逐次的なPython移植(第3回):Fortranのロジックを忠実にPythonへ置き換える
- ② NumPyによるベクトル化(第4回):PythonのループをNumPyの配列演算に置き換えて高速化
- ③ NumbaによるJITコンパイル(第4回):デコレータ一つでPythonコードを機械語にコンパイルして高速化
- ④ f2pyによるラッピング(第5回):ツールを使い、FortranコードからPythonラッパーを半自動生成
- ⑤ ctypesとbind(C)によるラッピング(第6回):FortranとPythonの標準機能のみで連携を実現
この記事では、これらのアプローチを「性能」「開発工数」「保守性」という多角的な視点から比較・評価し、あなたのプロジェクトに最適な解を見つけるお手伝いをします。
パフォーマンス分析
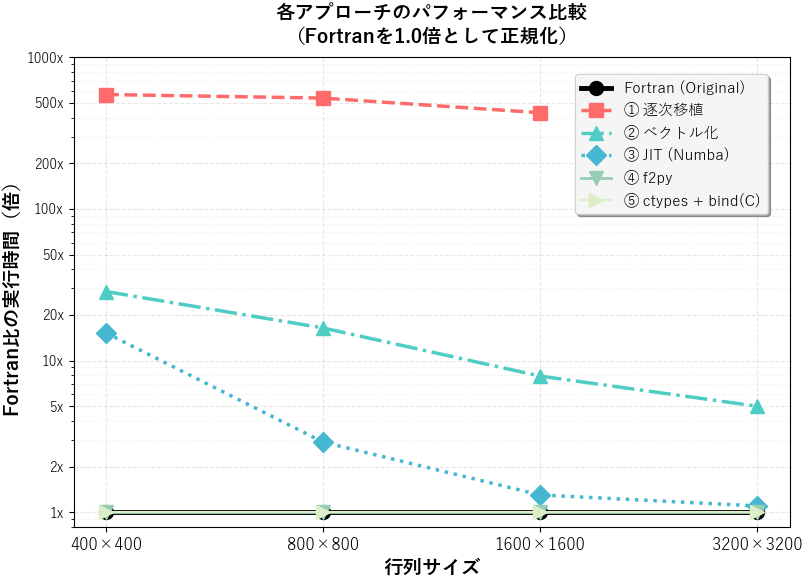
まずは各アプローチの核心となる計算性能を比較します。異なるサイズの行列データに対して特異値分解を実行し、その処理時間を計測しました。
ベンチマーク結果
下表は、オリジナルのFortran版を基準(1.0x)として、各アプローチの実行時間が何倍になったかを示しています。数値が小さいほど、Fortranの性能に近いことを意味します。
| 行列サイズ | Fortran (Original) | ① 逐次移植 | ② ベクトル化 | ③ JIT (キャッシュ後) | ④ f2py | ⑤ ctypes + bind(C) |
|---|---|---|---|---|---|---|
| 400x400 | 1.0x (0.17s) | 567.6x (97.06s) | 28.5x (4.87s) | 15.2x (2.60s) | 1.0x (0.17s) | 1.0x (0.17s) |
| 800x800 | 1.0x (1.38s) | 537.6x (739.26s) | 16.4x (22.55s) | 2.9x (3.97s) | 1.0x (1.34s) | 1.0x (1.34s) |
| 1600x1600 | 1.0x (13.28s) | 430.6x (5718.85s) | 7.9x (105.35s) | 1.3x (17.04s) | 1.0x (13.09s) | 1.0x (13.11s) |
| 3200x3200 | 1.0x (110.08s) | (計測対象外) | 5.0x (547.60s) | 1.1x (124.36s) | 1.0x (107.93s) | 1.0x (108.11s) |
考察
この結果から、各アプローチの性能特性が浮かび上がってきます。
ハイブリッド連携 (f2py, ctypes) はFortranと同等の性能 ラッパーを経由するハイブリッド連携アプローチ(④, ⑤)は、呼び出しのオーバーヘッドがほぼ無視できるレベルで、オリジナルのFortranと全く遜色ない性能を発揮しました。計算のコア部分をFortranが担当しているため、これは当然の結果といえるでしょう。
JIT (Numba) は強力 Pythonコードでありながら、大規模な計算になるほどFortranに肉薄する性能を示しました。初回実行時にはコンパイルのオーバーヘッドが発生しますが、その後の実行は高速です。
ベクトル化 (NumPy) も有効だが限界もある 逐次移植と比較すれば劇的に高速化されますが、JITやラッピングには及びません。すべてのループ処理をベクトル化できるわけではなく、無理に適用するとかえって性能が低下するケースもありました(第4回参照)。ただし、JITのような実行時オーバーヘッドがない点は強みといえます。
逐次移植はそのままでは実用的でない Pythonにそのまま移植したコードの性能は実用レベルには程遠い結果となりました。しかし、このコードは他のPython高速化手法の「土台」として、またロジックの正しさを確認するための「基準」として、重要です。
開発・運用面の比較
性能も重要ですが、開発工数や将来のメンテナンス性も無視できない要素です。
| アプローチ | 初期開発工数 | 内容 | 環境変化への脆弱性 | Fortran技術者依存 |
|---|---|---|---|---|
| ① 逐次移植 | 高 | Fortranロジックの完全な移植 | 最低 | 無し |
| ② ベクトル化 | 高 | 移植に加え、ベクトル化 | 低 | 無し |
| ③ JIT (Numba) | 高 | 移植に加え、JIT化 | 低 | 無し |
| ④ f2py | 低 | ツールによるラッパーの半自動生成 | 高 | 有り |
| ⑤ ctypes+bind(C) | 中 | C互換インターフェースの手動実装 | 低 | 有り |
各アプローチの総評
性能と開発・運用の両面を踏まえて、それぞれのアプローチを総括してみましょう。
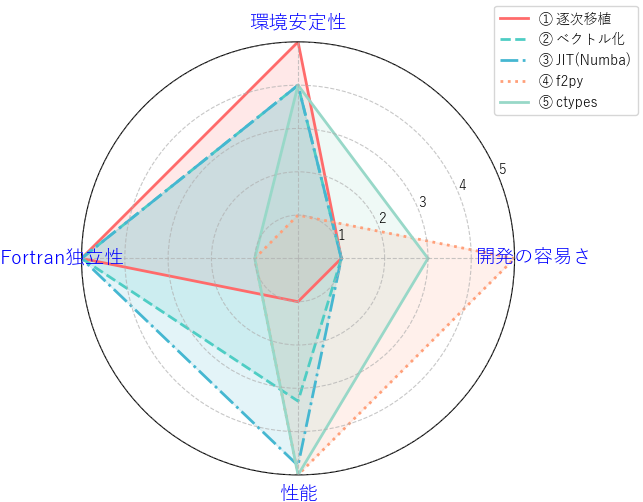
① 逐次移植 性能面では実用的とは言えません。しかし「完全移行」方針の出発点と言う重要性があります。
② ベクトル化 (NumPy) NumPyの扱いに長けていれば、コードをよりPythonらしく、簡潔に記述できる可能性があります。しかし、ベクトル化の適用可能な場面が限定され、パフォーマンスもJITに及ばないことが多いため、第一選択肢にはなりにくいかもしれません。
③ JIT (Numba) 「完全移行」方針における現実的かつ強力な選択肢です。元のPythonロジックをほぼ変更せず、デコレータを追加するだけでFortranに近い性能を達成できる可能性があります。小規模計算でのオーバーヘッドは弱点ですが、それを補って余りあるメリットがあります。
④ f2py 手軽さと高い性能が最大の魅力です。「とにかく早くPythonから使いたい」というニーズに応える最速の手段といえます。一方で、Pythonやコンパイラのバージョンアップで容易に動作しなくなる環境依存性の高さは、長期運用における大きなリスクです。
⑤ ctypes + bind(C) ラッパーを手書きする手間はかかりますが、最も堅牢でポータビリティ(移植性)の高い連携方法です。FortranとPythonの標準機能だけで完結するため、f2pyのような環境依存の問題がほとんどありません。長期的に安定して利用する「計算資産」の構築に適したアプローチです。
あなたの状況に最適なのは? シナリオ別推奨アプローチ
最終的にどの手法を選ぶべきでしょうか。それはあなたのチームの状況やプロジェクトの目的によって異なります。ここでは代表的な3つのシナリオを想定し、それぞれに推奨されるアプローチを提案します。
シナリオ1:将来的にFortran技術者の確保が見込めず、完全に脱却したい
この場合、目指すべきは「完全移行」です。
- 推奨アプローチ:③ JIT (Numba) による高速化 FortranコードをPythonに逐次移植した後、JITコンパイルするのが最も有望な選択肢です。これにより、Fortran依存を完全に断ち切りながら、計算性能を実用レベルに維持できる可能性が高くなります。
シナリオ2:実績あるFortranコードを、今後も資産として使い続けたい
計算コアの信頼性を重視し、「ハイブリッド連携」を選択するのが合理的です。
長期的な安定性を求めるなら:⑤ ctypes + bind(C) 環境変化に強く、透明性の高いこの手法が最適です。初期コストはかかりますが、将来にわたって安心して使える堅牢な資産を構築できます。
迅速な連携を優先するなら:④ f2py 「まずは動くものを作りたい」という状況では、f2pyの手軽さが光ります。ただし、将来のメンテナンスリスクを許容できる場合に限られます。
シナリオ3:段階的に移行を進め、最終的にはFortranから脱却したい
一度に完全移行するリソースがない場合は、段階的なアプローチが有効です。
第1段階 (短期的解決): まずは ④ f2py を使い、迅速にPythonからFortran資産を呼び出せる環境を構築します。これにより、Pythonエコシステムとの連携をすぐに始められます。
第2段階 (長期的解決): f2pyで連携しつつ、裏側で ③ JIT (Numba) による完全移行 を並行して進めます。移行が完了した時点で、f2pyのラッパーをJIT化されたPythonコードに差し替えることで、スムーズにFortran依存から脱却できます。
まとめ
本シリーズでは、Fortranで書かれた数値計算コードをPythonから活用するための5つのアプローチを実際に検証しました。
パフォーマンス検証の結果:
- ハイブリッド連携(f2py、ctypes)はFortranと同等の性能
- NumbaのJITコンパイルは大規模計算でFortranに近い性能を達成
- NumPyのベクトル化は改善効果はあるが限定的
- 単純な逐次移植は実用的な性能ではない
実用上の観点から:
- 長期運用なら ctypes + bind(C):環境依存が少なく最も安定
- Fortranから完全脱却なら Numba:Fortran技術者への依存をなくし、開発体制をPython中心に統一できる
- 即効性なら f2py:最も手軽だが環境依存のリスクあり
どのアプローチを選ぶかは、チームのFortran保守能力、性能要求、開発期間などの制約によって決まります。段階的な移行を考えている場合は、f2pyで当面の連携を実現しつつ、並行してNumbaでの移行を進めるという選択肢もあります。
本シリーズで使用したコードとベンチマークスクリプトは以下で公開しています。
Fortran-Python-Integration.zip