
本シリーズに含まれる以前の記事は、
nAG Toolbox for MATLAB® 製品の使用例 - Part 1
nAG Toolbox for MATLAB® 製品の使用例 - Part 2
の 2 つです。ここでもその続きとして他の nAG 関数を例に取り、
MATLAB® 中からそれをコールする方法、
及び結果を MATLAB® のプロット機能で表示させる方法について説明して行きます。
The G13 chapter - Time series analysis
時系列分析
時系列データというのはある時間依存型のプロセスに関し、 種々の時点で収集された観測値の集合のことを意味します。 nAG ライブラリの G13 章には時系列データの統計的構造を分析、 モデル化するための関数が収納されています。 これらの関数により構成されるモデルはデータをより良く理解するために、 あるいは系列から予測を導くために使用されます。 一例としてARIMA(autoregressive integrated moving average)モデルを時系列データにフィットさせてみましょう(下記参照)。
時系列データを最初に特徴付ける一つの方法は自己相関関数を計算することです。 これは底流にあるプロセスの異なる時点における挙動の間に存在する相関(すなわち依存性の度合い)を表します。 異なる時点間の間隔は遅延(lag)と呼びますが、その場合、自己相関関数は通常、 異なる遅延の値に対する自己相関係数の集合として表現されます。 g13ab という関数によりこの計算が行えますが、 それは同時に平均とか分散といったより基本的な統計量も算出します。 コードの例を次に示します。
% Here's the time series data (this comes from
% sunspot readings).
x = [5; 11; 16; 23; 36;
58; 29; 20; 10; 8;
3; 0; 0; 2; 11;
27; 47; 63; 60; 39;
28; 26; 22; 11; 21;
40; 78; 122; 103; 73;
47; 35; 11; 5; 16;
34; 70; 81; 111; 101;
73; 40; 20; 16; 5;
11; 22; 40; 60; 80.9];
% nk is the number of lags for which the autocorrelations
% are required.
nk = int32(40);
% Call the nAG routine.
[xm, xv, coeff, stat, ifail] = g13ab(x, nk);
遅延時間は離散値であるため、自己相関関数の表示には次に示すようなヒストグラム (コンテキストから autocorrelogram と呼ばれることもあります)を使用するのがベストです。
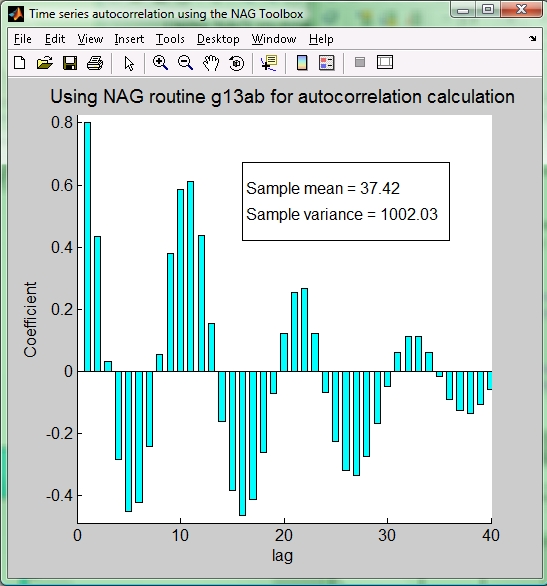
Figure 1: 時系列データの自己相関関数
自己相関関数には底流プロセスの時間依存性に関し、定量的情報と定性的情報の双方が含まれています。 この例の場合、振幅の周期から 11 単位での季節性(seasonality)が認められます。 それに加えて自己相関プロットの形状から、 時系列データに対し ARIMA モデルを適用する際のモデルパラメータの適正値について情報を抽出することもできます。 曲線は早期に 0 に漸近すべきです。 Figure 1 の場合のようにそうならないのは時系列データが非定常であることを示唆しており、さらなる処置が必要となります。 相関値が最初の数 lag の間高く、 その後すぐに 0 におさまる場合には移動平均(moving average (MA))型が示唆されますが、 正弦曲線形の形状の場合には通常自己回帰(autoregressive (AR))型と対応付けられます。 多くの場合、完全な形の ARIMA モデル(AR 要素と MA 要素双方を含んだモデル)がフィットのために必要となります。
自己相関関数の他に、部分自己相関関数のプロットからもさらなる知見が得られる場合があります。 これは上記のコード中、g13ab の代りに g13ac をコールすることにより作成できます。
The D01 chapter - Quadrature
数値積分
定積分(多次元の場合も含む)の値を数値計算で求めるという操作は頻繁に必要となるタスクです。 D01 章の関数はこの分野における種々のアルゴリズムを提供しています。 どの関数が使えるかは被積分関数の形式に依存します。 関数形が解析的な形でわかっている場合には一般的に d01aj が最適で、 被積分関数に特異点(特に代数的、あるいは対数的特異点)が含まれる場合でも使用できます。 他の特化した関数には振動型の被積分関数を扱う d01ak や、 既知の点で不連続性を持った被積分関数を扱う d01al などがあります。
d01aj で実装されているアルゴリズムは適応型(adaptive)です。 すなわち積分に使用する区間の幅は精度要件 (下記コードフラグメントにおいては変数 epsabs と epsrel によって指定されています) が満たされるようになるまで何回も分割されます。
次に示すのは積分計算用の関数をコールするコードです。
epsabs = 0.0;
epsrel = 0.000001;
% lw & liw are the dimensions of the w and iw output arrays. lw
% should be between 800 & 2000; liw should be a quarter of that.
lw = int32(1000);
liw = lw/4;
iw = zeros(liw, 'int32');
w = zeros(lw, 'double');
% Call the nAG routine, and check for errors.
[result, abserr, w, iw, ifail] = d01aj(func, a, b, epsabs, epsrel);
if ifail ~= 0
disp([' Non-zero ifail after d01aj call ', num2str(ifail)]);
return;
end;
このフラグメントにおいて、d01aj に引き渡される変数 func は MATLAB® m ファイルの名称を含む文字ストリングです。 このファイルには与えられた点における被積分関数の値を応答として返す関数が含まれていなくてはなりません。 サンプルファイルの内容を次に示します。
function [result] = myfunc(x)
result = x^2*abs(sin(5*x));
(これは次の Figure 2 に示されている被積分関数です)。 積分の近似値(result)に加え、d01aj の出力には最終的な刻み幅とそれに伴う誤差の情報が含まれています (これらの配列情報を MATLAB® のプロット関数が扱える形にするには多少の操作が必要です)。 Figure 2 は個々の刻みが積分にどれだけ寄与したか、及び付帯する誤差の大きさをプロットしたものです。 この被積分関数の場合、関数の変化が急なところではより細かい刻み幅が用いられていることがわかります。 比較的大きな誤差に対応した小区間(関数値が 0 となる周囲)の刻み幅は実際非常に小さなものです。
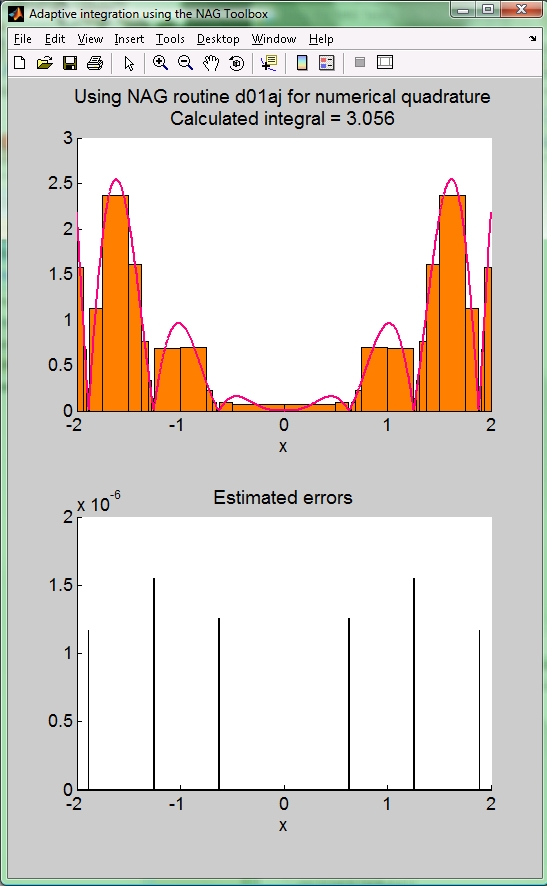
Figure 2: 積分の近似計算
The G03 chapter - Multivariate Methods
多変量解析
多変数のデータセットには多くの対象物に対し計測された多数の変数が含まれています。 そのようなデータセットは科学のあらゆる分野で生じますが、 それらの解析には nAG ライブラリの G03 章に含まれる関数が使用できます。 例えばミズハタネズミのどれだけの種が英国に存在しているかを調査するために、 環境科学者が 300 匹のネズミの頭蓋骨について 13 の特徴的計測の有無を調べたとしましょう。 英国と欧州大陸に広がる 14 の値域において観測が行われたとします。 欧州からのデータはすでに 2 つの種(A. terrestis と A. sapidus)に区分されています。 科学者たちの仕事は英国のデータがどちらの種に属するかを決定することです。
データの処理は各地域における計測値を平均化することから始まります。 これによって 13 個の変数各々について 14 個の観測データが得られたことになります。 これは 13 次元空間における 14 個の点と考えることができるわけですが、 このようなデータセットの分析には通常主成分分析(例えば g03aa 関数が該当します)の手法が用いられます。 これはデータセットの次元数をより小さな値に減らす手法です。 オリジナルデータの代りに、この低次元空間内に抽出された点の構造を調べることになります (ただし、それら抽出されたデータがオリジナルデータを適切に表現している場合に限ります)。 ネズミのデータセットの場合、 最初の 3 つの主成分だけではオリジナルデータの 65 %のバラツキしか説明できないため、 これでは十分とは言えません。
このような場合に用いられる別の手法としてはメトリックスケーリング(metric scaling)として知られる手法があります。 最初のステップは 14 x 14 の相違度行列(dissimilarity matrix)を構成することです。 この行列の各要素はオリジナルの 13 次元空間におけるデータペア間の距離を表します。 この相違度行列を計算するのが g03ea 関数で、コードは次のようになります。
% These are the region labels.
label = char( 'Surrey', 'Shropshire', 'Yorkshire', ...
'Perthshire', 'Aberdeen', 'Eilean Gamhna', 'Alps', ...
'Yugoslavia', 'Germany', 'Norway', 'Pyrenees I', ...
'Pyrenees II', 'North Spain', 'South Spain' );
% This is the vole data. 14 rows (one for each region),
% 13 columns (one for each variable).
data0 = [
[48.5 89.2 7.9 42.1 92.1 100.0 100.0 ...
35.3 11.4 100.0 71.9 31.6 2.8];
[67.7 67.0 2.0 23.0 93.0 100.0 86.0 ...
44.0 14.0 99.0 97.0 31.0 17.0];
[51.7 84.8 0.0 31.3 88.2 100.0 94.1 ...
18.8 25.0 100.0 83.3 33.3 5.9];
[42.9 50.0 0.0 50.0 77.3 100.0 90.9 ...
36.4 59.1 100.0 100.0 38.9 0.0];
[18.1 79.6 4.1 44.9 79.6 100.0 77.6 ...
16.7 37.1 100.0 90.4 9.8 0.0];
[65.0 81.8 9.1 31.8 81.8 100.0 59.1 ...
20.0 30.0 100.0 100.0 5.0 9.1];
[57.1 76.2 21.4 38.1 66.7 97.6 14.3 ...
23.5 9.5 100.0 91.4 11.8 17.5];
[26.7 53.1 23.5 38.2 44.1 94.1 11.8 ...
11.8 18.2 100.0 94.9 12.5 5.9];
[38.5 67.9 17.9 21.4 82.1 100.0 60.7 ...
35.7 24.0 100.0 91.7 37.5 0.0];
[33.3 83.3 27.8 29.4 86.1 100.0 63.9 ...
53.8 18.8 100.0 83.3 8.3 34.3];
[47.6 92.9 26.7 10.0 36.7 100.0 50.0 ...
14.3 7.4 100.0 86.4 90.9 3.3];
[60.0 90.9 13.6 68.2 40.9 100.0 18.2 ...
100.0 5.0 80.0 90.0 50.0 0.0];
[53.8 88.1 7.1 33.3 88.1 100.0 19.0 ...
85.7 9.8 73.8 72.2 73.7 2.4];
[29.2 74.0 16.0 46.0 86.0 100.0 18.0 ...
88.0 16.3 72.0 80.4 69.6 4.0];
];
% Invoke this standard transform to remove the effect
% of unequal variances between ranges.
data1 = asin(1.0 - 0.02*data0);
% Initialze D to zero before adding distances to D.
update = 'I';
% Distances are squared Euclidean.
dist = 'S';
% No scaling for the variables.
scal = 'U';
% Number of observations (regions in which data is gathered).
nobs = int32(14);
% Number of variables (measurements in each region).
nvar = int32(13);
% Which variables are to be included in the distance computation?
isx = ones(1, nvar, 'int32');
% Scaling parameter for each variable (not used, but must
% be supplied).
s = ones(1, nvar, 'double');
% Input distance matrix (not used, but must be supplied).
d = zeros(nobs*(nobs-1)/2, 1, 'double');
% Call the nAG routine to calculate the dissimilarity matrix.
% The string at the end of the parameter list signals an optional
% parameter of this name (m), whose value (nvar) follows it.
[sOut, dOut, ifail] = g03ea(update, dist, scal, nobs, data1, ...
isx, s, d, 'm', nvar);
次のステップは例えば 3 次元といった低次元空間における点間の距離を表す新たな行列を算出することです。 古い行列から新たな行列への射影にはメトリックスケーリングが用いられます。 次がコードの続きで、g03fa 関数をコールすることによってこのメトリックスケーリングが行われます。
% Standardize the matrix by the number of variables.
dOut = dOut ./ double(nvar);
% Now correct for the bias caused by the different number of
% observations in each region.
ns = [19 50 17 11 49 11 21 17 14 18 16 11 21 25];
jend = nobs-1;
for j = 1:jend
istart = j+1;
for i = istart:nobs
index = (i-1)*(i-2)/2 + j;
dOut(index) = abs(dOut(index) - (1.0/ns(i) + 1.0/ns(j)));
end
end
% Now prepare for the metric scaling from nvar to ndim dimensions.
roots = 'L';
ndim = int32(3);
[x, eval, ifail] = g03fa(roots, nobs, dOut, ndim);
最後に 3 次元空間中の点群を散布図の形でプロットします。
% Do the scatter plot of the 3D data.
scatter3(x(1:nobs), x(nobs+1:2*nobs), x(2*nobs+1:3*nobs), ...
40.0, colours, 'filled');
% Add the labels, coloured according to species.
dims = size(label);
for i = 1 : nobs
text(x(i), x(nobs+i), x(2*nobs+i), label(i,1:dims(2)), ...
'Color', [colours(i), colours(nobs+i), colours(2*nobs+i)], ...
'FontSize', 13);
end
結果を示したものが Figure 3 ですが、 この図から英国のデータ(黒色の点)は赤(A. sapidus)よりも青(A. terrestis)に近いことがわかります。 すなわちこれらのネズミは A. terrestis の一種であると考えられます。
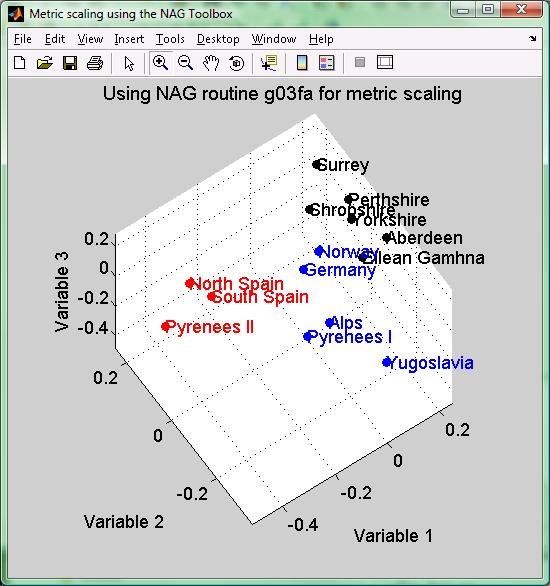
Figure 3: ネズミの種に関するメトリックスケーリングからの散布図
The G05 chapter - Random Number Generators
乱数発生機能
一連の乱数を信頼の行く形で発生させる機能は多くの計算分野 (例えばモンテカルロシミュレーション) において必要となります。 G05 章にはそのための関数が多数含まれていますが、 ここではそのうちの 2 つについて用例を示します。
この領域においては擬似乱数(pseudo random numbers)と準乱数(quasi random numbers)の違いに留意する必要があります。 擬似乱数の場合、その統計的な特性は“真の”乱数(本質的にランダムな物理的プロセスから得られるもので、 放射性物質のそばに置かれたガイガーカウンタのカチカチ言う音の時間差がその例)のそれに可能な限り近いものとなります。 例えば擬似乱数シーケンス中の隣接する数字間には無視できる程度の相関しかありません。 これに対し準乱数はそのような特性を持ちません。 それは空間的により均等な分布となるよう企図して生成されます。 この特性はモンテカルロ法に適したものと言え、 同じシーケンス長の場合に擬似乱数よりも正確な推定値をもたらします。
ここでは両者の違いが目で見てわかるようにしてみましょう。 次に示すのは 2 つの擬似乱数シーケンスを発生させるコードで g05fa 関数を使用しています。
% The number of (x,y) pairs to generate.
n = int32(10000);
% Specify the mechanism for generating pseudo-random numbers.
g05za('O');
% Now generate two vectors of n of them, in the interval [a,b].
a = 0;
b = 1;
[x] = g05fa(a, b, n);
[y] = g05fa(a, b, n);
これに対し次のコードは 2 次元の準乱数シーケンスを発生させるもので、 いわゆるフォーレ法に基づく g05yd を使用しています。
% The generator creates generate vectors of random numbers; % first, specify the length of each vector. idim = int32(2); % Initialize the Faure quasi-random number generator. [iref, ifail] = g05yc(idim); % Now generate n 2D vectors of them. [quasi, irefOut, ifail] = g05yd(n, iref);
それぞれのシーケンスを 2 次元空間上の点の集合ととらえた場合、 それらは散布図としてプロットできます(Figure 4 参照)。 この結果から 2 種類の乱数の違いを見て取ることができます。 共に 2 次元空間をランダムに満たしているように見えますが、 準乱数シーケンスの方がより均等に散らばっていることがわかります (技術的に言うと、シーケンス中のそれぞれの数が他の数と最もぶつからないような形で生成されているからです)。
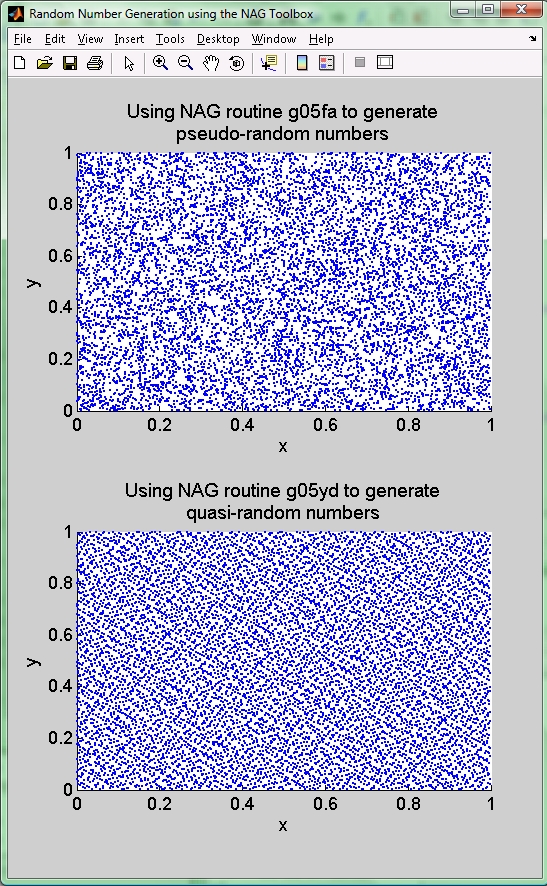
Figure 4: 2 種類の乱数発生